Measuring the unmeasurable — inspiration from baseball
The New School approach to information security promotes the idea that we can make better security decisions if we can measure the effectiveness of alternatives. Critics argue that so much of information security is unmeasurable, especially factors that shape risk, that quantitative approaches are futile. In my opinion, that is just a critique of our current methods and instruments, not any proof of ultimate feasability. What we need is major innovations in metrics, instrumentation, and such.
We can take inspiration from other fields. Consider this innovation in statistical value management in baseball, a.k.a. the “Moneyball” approach:
Evaluating fielding is baseball’s hardest math. There are just too many unknowns in a play. How much ground did Jeter cover? How fast was the ball moving? In essence: How unlikely was it that he’d catch the ball? […]
Sportvision’s FieldFX camera system records the action while object-recognition software identifies each fielder and runner, as well as the ball. After a play, the system spits out data for every movement: the trajectory of the ball, how far the fielder ran, and so on. “After an amazing catch by an outfielder, we can compare his speed and route to the ball with our database and show the TV audience that this player performed so well that 80 percent of the league couldn’t have made that catch,” says Ryan Zander, Sportvision’s manager of baseball products. That information, he says, will allow a much more quantitative measure of exactly what is an error.
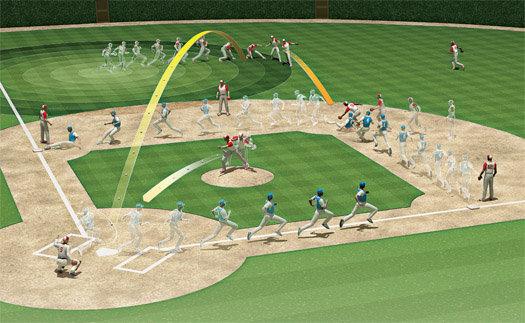
The issue here is incentive. No one produces this kind of tech without a hellacious financial incentive. There appears to be none in information security. My guess if you started fining CEOs, CTOs and CFOs personally you’d see innovation that would make the kind of tech on display here look like cheap cinematic tricks from the 50’s.
Wow, I’ll have to challenge that 🙂
Take, for instance, the “80 percent of the league couldn’t have made that catch” thing. Thinking on the nice work from Nassim Taleb (the Black Swan guy), people (and so outfielders) physical attributes are usually only slightly different. Checking the past features from league outfielders should not give you enough information to say something like that, specially considering the interval between the games and the constant training for the athletes. It’s too much conclusion based on past data that don’t have a direct causality relation with the event you are trying to predict.
That is also common on security. With the speed of changes and complexity of IT systems, constant changes of user behaviour due to those new systems (social networks?), it is extremely hard to produce a decent forecast of future events based on past data. Why would all the data about the exploitation of OS and web servers vulnerabilities from the past decade be useful to determine exploitation trends of browser vulnerabilities or XSS on social network websites?
We should be a little more skeptical on our ability to forecast events, specially security incidents.
Good points, Augusto.
If the “risk management” approach (a.k.a. Moneyball applied to InfoSec) was about forecasts based on statistical analysis of history, I would totally agree with you, not only for the reasons you mention but also others.
It’s not just the Black Swan phenomena. Sadly, Taleb’s popular book did a very poor job of explaining the random process behind Black Swan phenomena. You have to go to his technical papers, and also technical and academic papers of other people. So it’s very common for people to equate “Black Swan” with any process that defies statistical analysis, forecasting, and prediction. To understand how mistaken that is, consider that this category includes four completely different processes:
* Non-stationary random processes
* Higher-order correlation structures
* Self-referential processes (aka scale-free, chaotic)
* Strategic game process (actors who might mimic randomness when they choose)
Back to your main points…
Because information security risk is not driven by the same class of processes as physical and skill variations, and because of non-stationarity, fast evolution of threats and technology, etc., that forces us to use inference and analysis methods that pick up where the traditional methods leave off.
To some people in InfoSec, this is absurd, silly, or hopeless. Many of the nay-sayers regarding risk measurement and management hold this position.
However, to some of us, this is an exciting research challenge. Yes, “research” in the sense of theory and academia and first principles.
This also means that no amount of traditional statistical crunching on piles of data will ever arrive at aggregate risk metrics that satisfy minimum thresholds of reliability and credibility.
So… contrary to Adam’s post, models do matter, especially when you are trying to put all security metrics together to estimate aggregate risk.
Here at Newschool I’ve posted on the new methods and approaches that I think will help get us to the Promised Land. One thing for sure — to get there, we won’t be attempting to forecast. Instead, we will aim to generate meaningful signals for action, especially in the form of incentives.
You know, the best days are those with good debates like this. Good compensation for not being at RSA 🙂
I think that the research makes sense. But I also think that the results so far are close to zero. Almost all organization wide risk assessments I’ve seen are not so far from pure fiction and wishful thinking.
Actually, I’m interested on the next step, the decision-making process. Like when you mention a model to estimate aggregate risk. Interesting, but it’s hard to see how we could base decisions on that. Is this aggregate risk too low or too high? Even with some benchmarking in place for that, if we don’t try to forecast it’s hard to say how our actions will impact those numbers. It’s useful to ensure that you are doing the minimal, fighting Today’s main threats and working on the most exploited vulnerabilities, but we still don’t have anything that help us to decide on medium and long term. And that’s only for which controls to implement and class of vulnerabilities to fix, when we include the decision class of which systems/environments/LOBs to address inside the organization, it becomes even harder, specially because those benchmarks will not help at all.
Ok, I confess I’m one of the “nay-sayers” :-), but that’s not only for the sake of saying that everybody is wrong and the world is going to end because everything now is working over port 80 (I’m already sounding like a security rockstar). I’m curious too see defense strategies and decision-making models that won’t rely on those models. Honestly, except from some quite naive approaches, haven’t seen any so far.
Yes, I agree that the research results to-date have been close to zero. I’ve spent several years trying to understand why. Suprisingly, the main reason seems to be that the people and institutions that fund research in InfoSec risk analysis (a.k.a. economics of InfoSec) have not made *solutions* a priority. There are a small handful of researchers scattered across the globe, but none (as in zero) have adequate funding, resources, or sponsorship to do the kind of reasearch necessary.
There’s also a very strong cultural bias in the engineering and hard science communities. To put it bluntly, “solutions” = technical and technological. This makes it hard or impossible to propose research projects that have no technological product, but instead aim to produce a social or economic system or process. To engineers, this feels too squishy and “not real science”.
There’s a big difference between being a “nay-sayer” and a “skeptic”. At worst, the nay-sayer is against any effort to solve the research problems because they believe that such effort is futile or wasteful or counter-productive. IMHO, that approach is not distinguishable from a position based on defeatism and cynicism. Dig deeper, and you’ll find both arrogance and fear.
In contrast, the skeptical view is very compatible with real scientific progress, including revolutionary breakthroughs. The skeptical view simply demands the highest standards of proof, experimental tests, critical thinking, challenging evaluations, etc.
I’m both skeptical and also hopeful regarding this line of research. I go back and forth between being optimistic and pessimistic. But we’ll never know unless we give it a serious try.